Anton Chuvakin has been working with SIEM technology for a long time. Twenty years in fact. I've followed him online for many years, listening to his talks, and gained wisdom from his insights. While I don't always agree with him. I respect the breadth of his knowledge, experience, and contributions to the industry. Which is why, when he posted his 20 Years of SIEM blog, I couldn't figure out why reading it made me angry.
0 Comments
In the early part of January 2021, some tweets appeared by @likethecoins regarding a research study that was published on the effectiveness of Endpoint Detection and Response (EDR) tools. Here's the TL;DR A group of Greek researchers performed an analysis of multiple EDRs against four common multistage attacks. They evaluated the ability of the EDR to detect and block each attack. Only two successfully alerted and blocked all four attacks (Sentinel One with test features and FortiEDR). They are still in the process of following up with some vendors as they mistakenly tested an EPP product instead of the EDR product or they tested the EDR product without the full set of available features. Most notable product missing from their testing? FireEye HX. I have not seen any note as to why their product was not included. The great this is that their research methods are transparent and those methods, tools, and configurations are published in the original paper so others can duplicate the study if desired. Updated result table (key is underneath): 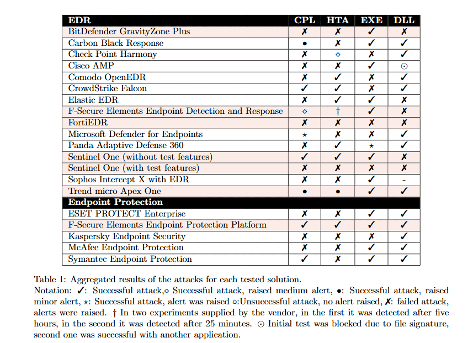 Some thoughts:
1. The EDR tools do not perform as people expect them to; that is, they do not detect and block badness as most defenders define badness. 2. They lean toward the permissive because they don't want to impact operations. So an activity that is bad 99% of the time because normal users do not do those things, is not often flagged or blocked or (sometimes) even logged. This is an activity that would (should) be alerted and investigated were it in a SIEM with and would have a low FP rate. But as @likethecoins says: There are many legit applications that perform actions that look malicious, but are actually benign. The process of determining what behaviors are malicious or not takes careful analysis and often depends on the specific environment. But this leads to a false assumption that EDRs provide MORE protection than they actually do. 3. One important issue found by the researchers is that many EDRs do not log activity, or keep the logs for long. This means that if malicious activity is detected via other means (firewall, IDS, NDR, SIEM), the EDR might not have a record of it and thus the timeline tools within the EDR won't help the analysts. 4. To be most effective, the tool (and the people using the tool) must 'know' the environment. But the ability to create custom rules and alerts varies by EDR. This would be critical to being able to customize the EDR to the environment it is in. 5. The study emphasizes that tools do not and cannot replace people. Articles with follow up and updated information: https://www.scmagazine.com/analysis/endpoint-security/edr-study-to-undergo-re-tests-after-misclassification-error-with-selected-systems https://therecord.media/state-of-the-art-edrs-are-not-perfect-fail-to-detect-common-attacks/ Some years ago there was a bit of a debate among some NOVA Hackers about the best way to make coffee. At the time I liked coffee, but I didn't know much about how it could or should be made. Except maybe drop the pod into the machine and hit start or place an order at Starbucks. So I volunteered to do some research and present a talk at one of the NOVA Hackers meetings. At that time select talks were being recorded by one of our members, Brett Thorson, as permitted by the speaker. I allowed this talk to be recorded. This talk completely changed how I viewed, bought, and brewed coffee. The research I did for this talk taught me that most coffee is old and stale when bought from the store or made at most shops and restaurants (including Starbucks!). Also, it is usually not made correctly. The beans may not be ground correctly, the temperature of the water is wrong, or the amount of time the grounds are immersed in the water is too short or too long. Furthermore, most home coffee brewers do not properly heat the water or immerse the grounds for you. The result is coffee that is too weak, or too strong, or too bitter, or too bland. It would wake you up, but drinking it would not be an enjoyable experience. Now some of you may be thinking the same thought as one of my friends who says: "The only bad coffee, is no coffee." But I learned that the extra effort that goes into making a really good cup of joe is not as time consuming as you may think. And once you have done it a few times, it will be a smooth part of your routine. Too many people are settling for the equivalent of heating up frozen chicken tenders when they could be making and eating cordon bleu. After doing this talk, I starting buying only beans that were freshly roasted (examples: 1, 2, 3, 4). I got rid of our Keurig. I started using the burr grinder that my wife bought. And now I make coffee either with a french press (lots of choices, I suggest stainless steel) or with a pour over. I have not bought a good coffee brewers, but I know that I cannot get away with the $24.99 Amazon special. All of this adds about five (5) minutes to my morning routine, but it has made my morning routine so much more enjoyable. So here is the video from December 2013. I hope you enjoy and learn something. NOTES: 1. During this talk, I forgot to mention that the type of water is important. My suggestion is to use filtered water. 2. The group was pretty rowdy that night. Don't let the interactions between myself and the audience distract you. So a while back I wrote a blog post about integrating Mark Baggett's freq_server into Splunk (Here). I then referenced it a few times and told some people about it, but I didn't think about it much.
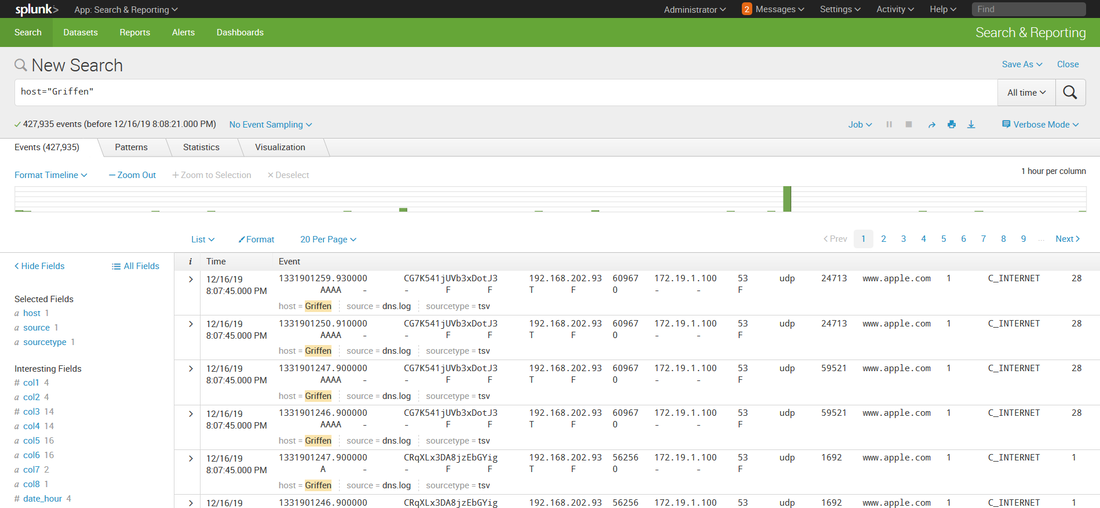
Then, while working on prepping to teach 555, I decided to build it into my class demonstrations. So I opened up the blog, followed the instructions, ran my search.... and it didn't work. Badly. I'll cut the melodrama short, but suffice to say after a frustrating day of troubleshooting, I got it working again. Below is the updated transforms.conf file you need to use if you have Splunk version 8. [freqserver] external_cmd = freq.py domain external_type = python python.version = python2 fields_list = domain, frequency I still need to update this for Mark's new version of freq_server. So watch this space for another blog post in a couple of days. A couple of months ago I was asked if I could create a private index in Splunk (<8.0) that only certain users could see. Heck, I said, that was easy. Configuring roles for that was well documented. Then I was told that those users also needed to upload data into that index. Whoa.... now THAT presented a little bit of a conundrum. I didn't want to give those users admin access to my Splunk just so they could upload data. But there didn't seem to be a clear built in role for 'data upload'. I did some Google research and found several posts on answers.splunk.com that gave me some direction, but none worked quite the way I wanted. Piecing the information together from all the posts I had read, I come up with a set of permissions that worked to create a role that could search, report, alert, etc (user permissions) and also upload data. So let me describe how to set this up in your environment. First I created the following authorize.conf file in $SPLUNK_HOME/etc/system/local: [role_user] NOTE: Replace anywhere you see <index> with the name of your index (i.e. my_private_index). ALSO NOTE: I commented out the user and power user inheritance. If you didn't, you would also inherit the restriction on the very index you want this role to view! Then I created an index in my Splunk index. Below is a quick walk through if you are not already familiar with the process. I didn't do anything special to create this index. While the pictures below show a stand alone Splunk server, at work I have an index cluster. After I created the index, I created two users, Bob and Alice. Bob I left as a regular user and Alice I gave the new role I created above. 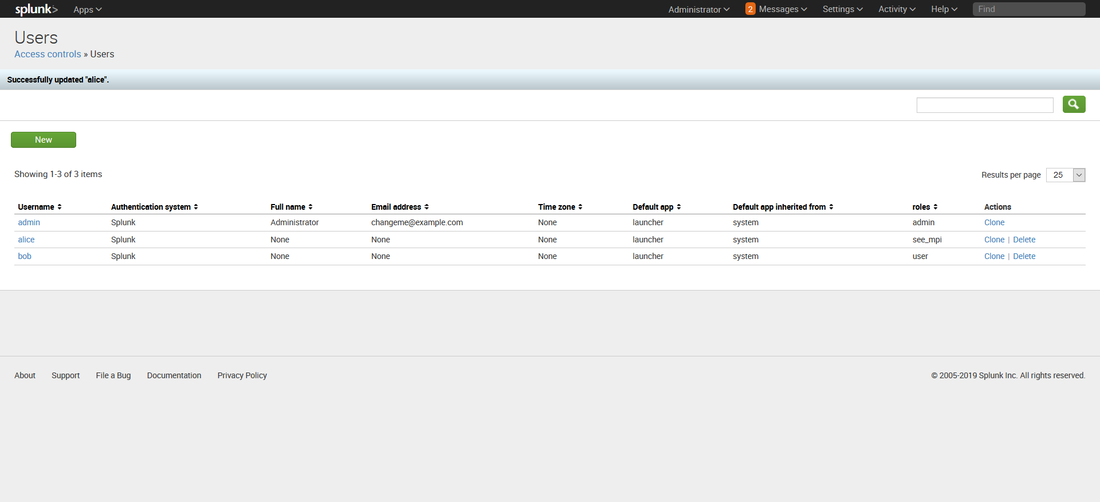 Now, when I logged in a Alice, I could see all the data in my index. 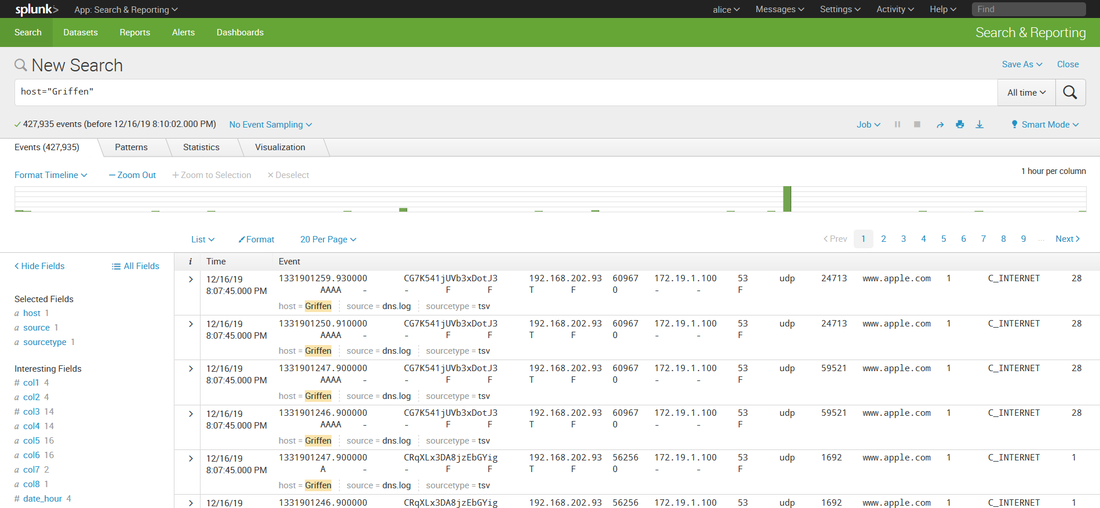 But Bob cannot see anything in that index, even if he searches specifically for it: 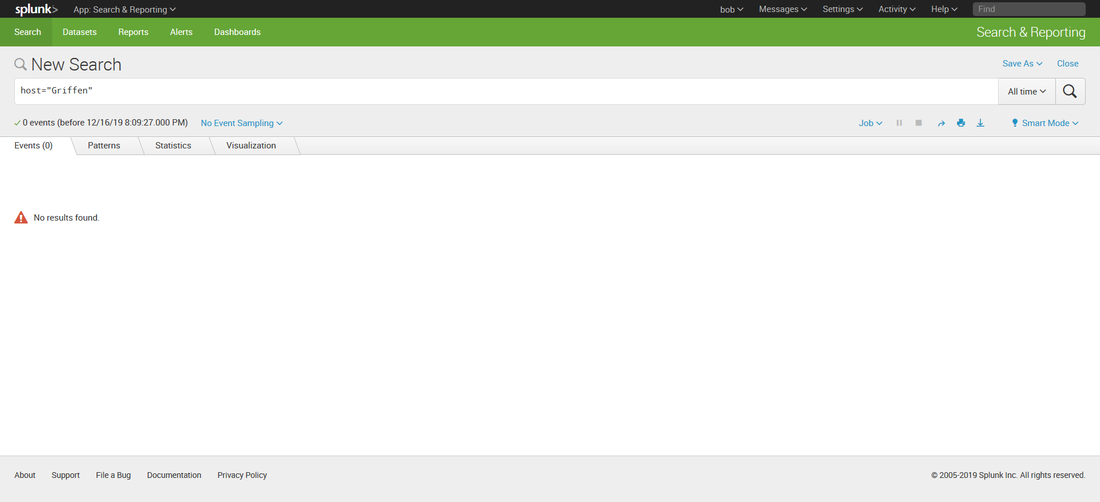 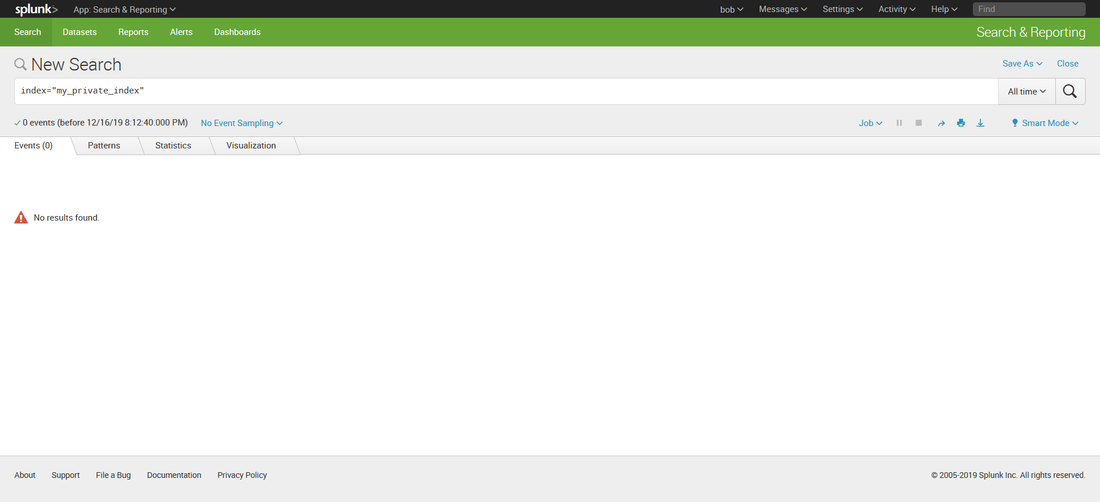 Alice can also add data to that index: 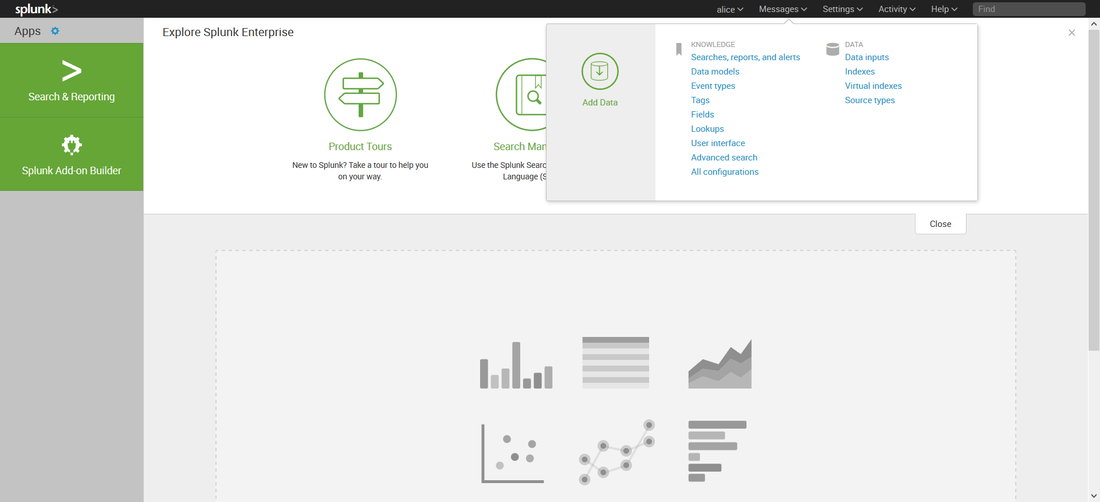 There are some caveats with regards to risks to the integrity and confidentiality of the data in the private index:
 I hope this helps some folks who have a unique situation. Let me know any suggested improvements or comments. |
AuthorCraig Bowser works as a network security professional who is a Christian, father, geek, scout leader, and occasional woodworker Archives
February 2022
Categories
All
|
 RSS Feed
RSS Feed